Hashing
Page content
Hash table
class HashTable:
def __init__(self, elements):
self.bucket_size = len(elements)
self.buckets = [[] for i in range(self.bucket_size)]
self._assign_buckets(elements)
def _assign_buckets(self, elements):
self.buckets = [None] * self.bucket_size
for key,value in elements:
hashed_value = hash(key)
index = hashed_value % self.bucket_size
# looks for an empty bucket to store the data
while self.buckets[index] is not None:
print(f"The key {key} collided with {self.buckets[index]}")
index = (index + 1) % self.bucket_size
self.buckets[index] = ((key, value))
def get_value(self, input_key):
hashed_value = hash(input_key)
index = hashed_value % self.bucket_size
while self.buckets[index] is not None:
key,value = self.buckets[index]
if key == input_key:
return (value)
index = (index + 1) % self.bucket_size
if __name__ == "__main__":
capitals = [
('France', 'Paris'),
('United States', 'Washington'),
('Italy', 'Rome'),
('Canada', 'Ottowa'),
]
hashtable = HashTable(capitals)
print(hashtable)
print(f"The capital of Italy is {hashtable.get_value('Italy')}")
## Inside class HashTable...
# separate chaining ?
# def _assign_buckets(self, elements):
# for key, value in elements:
# hashed_value = hash(key)
# index = hashed_value % self.bucket_size
# self.buckets[index].append((key, value))
# def get_value(self, input_key):
# hashed_value = hash(input_key)
# index = hashed_value % self.bucket_size
# bucket = self.buckets[index]
# for key, value in bucket:
# if key == input_key:
# return (value)
# return None
##
Hashmap (Dictionary, Map, Hash Table, Associative Array)
- A hashmap is a set of key-value pairs.
- It maps keys to values for highly efficient lookup.
O(1)for add, delete, or get.- If collisions occur too much, the worst case runtime is
O(N). Otherwise,O(1). - A balanced binary tree implementation gives us an
O(logN)lookup time.- It uses less space.
- Each key is unique.
- Use
dictin python.
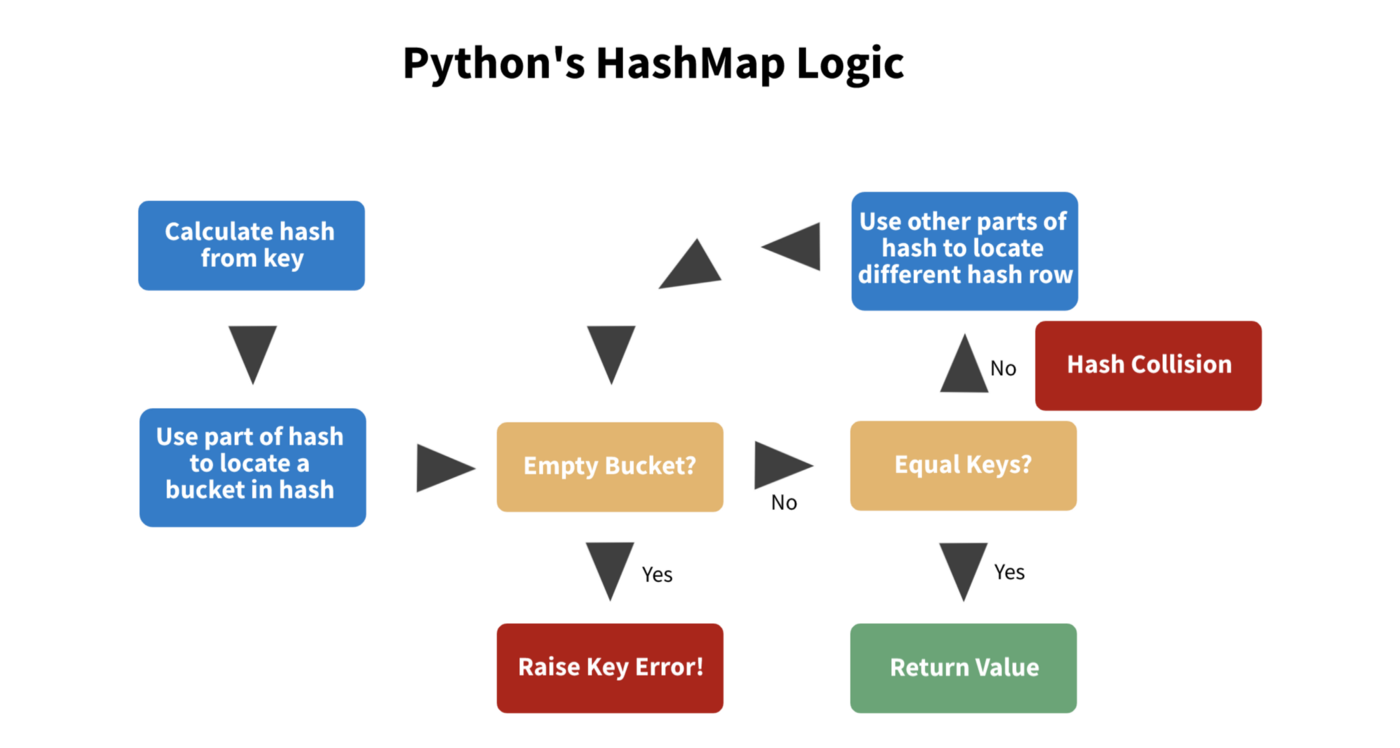
Insertion of a key and value
-
Compute the key’s hash code, usually
intorlong. -
Map the hash code to an index in the array.
- i.e.
hash(key) % array_length - There is a linked list of keys and values at this index.
- We can have multiple keys with the same hash code or
- Two different hash codes that map to the same index.
- i.e.
-
Store the key and value in this index.
Retrieve the value pair by the key
- Compute
hash(key)and index fromhash(key). - Search through the linked list for the value with this key.

Hashing
-
An object is hashable if it has a hash value which never changes during its lifetime.
- atomic immutable types
- str
- bytes
- numeric types
- a frozen set, by definition
- a tuple, if all its items are hashable
-
Hashable objects which compare equal must have the same hash value.
Collision resolution
1. Separate chaining
- Chaining represents a hash table as an array of
mlinked lists(“buckets”). - The _i_th list contains all the items that hash to the value of
i. - Search, insertion, and deletion are reduced to the linked list problems.
- If
nkeys are distributed uniformly, each list will containn/melements. - Sequential probing: Inserting an item into the next open cell in the table.
2. Open Addressing
- If the bucket you should use is busy, you just keep searching for a new bucket to be used.
- It maintains the hash table as a simple array of elements (not buckets).
- Required changes:
- How to assign buckets to new elements
- How to retrieve values for a key
- The main problem:
- You have to handle the deletions of elements in your table.
- To delete an element you have to replace its bucket with a dummy value, which indicates to the interpreter that it has to be considered deleted for new insertion but occupied for retrieval purposes.
- You have to handle the deletions of elements in your table.
Problems with hashing solutions
- Is a given document unique within a large corpus?
- Compare
H(document)with the rest of the corpus to check for a collision.
- Compare
- Is part of this document plagiarized?
- Build a hash table of substrings of length
win all the documents in the corpus.
- Build a hash table of substrings of length
- How can I convince you that a file isn’t changed?
Minwise hashing
- Compute the hash code $h(w_i)$ of every word in $D_1$ and select the code with the smallest hash code.
- Compute the hash code $h(w_i)$ of every word in $D_2$ and select the code with the smallest hash code.
- Compare the
ksmallest with Jaccard similarity .
Perfect hashing
- It guarantees zero collision.
- It makes use of two-level hashing.
- The first level is similar to hashing by chaining.
- The second level chain is replaced with a hash table.